이 누리집은 대한민국 공식 전자정부 누리집입니다.
메뉴
전체메뉴
연구사업
연구자원
연구성과
알림자료
연구원 소개
누리집모음
연구사업
연구자원
- 바이오자원
- 데이터 · 지식자원
- 임상연구지원 · 시설
연구사업
헬스케어인공지능연구
- 수정일
- 2025-12-04


개요
- 개인의 맞춤형 건강관리 기술개발을 위해 다양한 헬스케어 데이터를 활용한 인공지능 기술을 적용 및 대규모 컴퓨팅 기반 인공지능 기법을 개발 연구를 수행하고 있습니다.
내용
-
거대 언어 모델(Large Language Model)을 활용한 인공지능 기반 유전변이 분석 지원 알고리즘을 개발하여, 유전체 기반 유전변이 연구 및 의료 분야에서의 활용 가능성을 높이기 위한 연구를 수행하고 있습니다.
- 다양한 질환의 연구결과 및 공개 유전변이 정보를 활용한 학습용 데이터 구축, 유전변이 결과 레포트, 거대 언어 모델 기반 유전변이 해석 서비스 구축 및 활용 방안을 도출할 예정입니다.
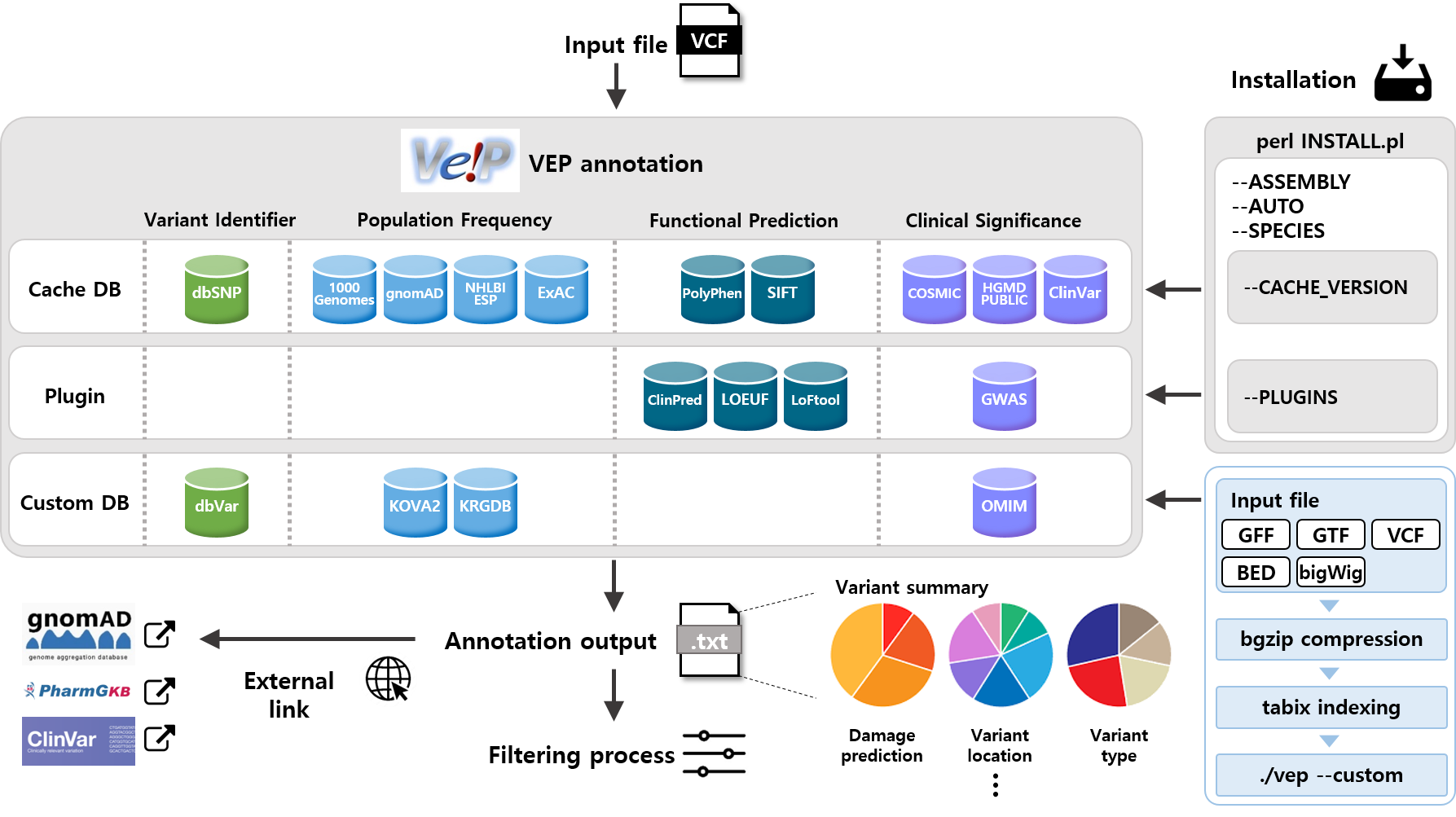
유전변이 주석 정보 수집 및 데이터베이스 구축 개요도
-
비정형 의료 데이터(간호기록지, 폐영상 검사 판독 결과지) 전처리 파이프라인을 구축하고 인공지능 분석 알고리즘 개발을 통해, 비정형 의료 데이터 분석 사례 마련 및 절차를 공유하고자 기술개발 연구를 수행하고 있습니다.
- 비정형 데이터 전처리 인공지능 알고리즘은 룰기반 및 자연어처리(Natural Language Processing, NLP) 알고리즘을 활용하여 데이터 정제 및 표준화를 수행하고, 언어모델을 활용한 의미 추출 및 분석을 진행하며, 최종적으로 데이터 통합 및 분석을 수행할 예정입니다.
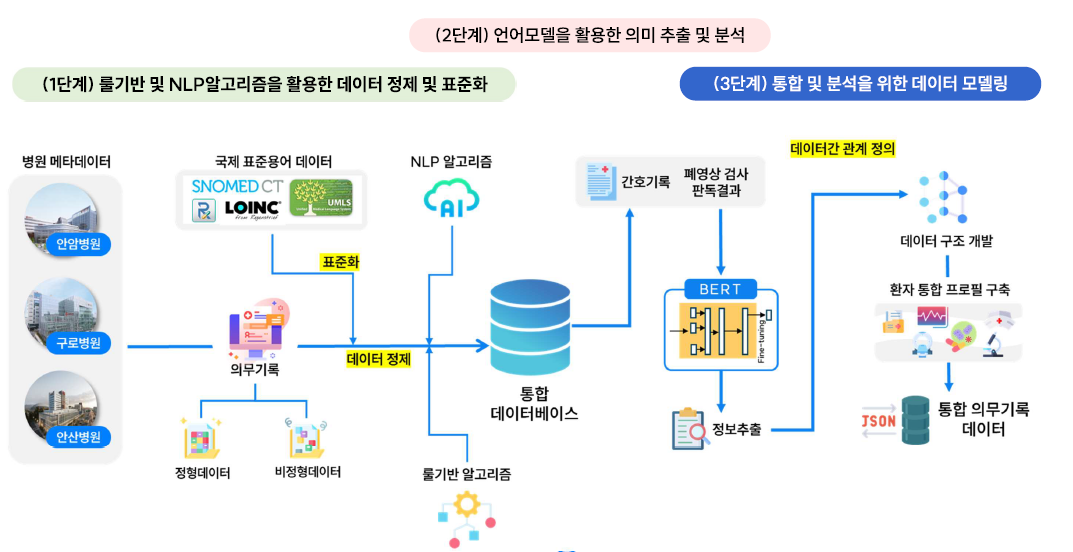
인공지능 알고리즘 기반 비정형 의료 데이터 통합 구축 개요도
-
인지장애 예측을 위해 다양한 헬스케어 데이터를 체계적으로 전처리를 수행하여, 인공지능 기반 분류 및 예측 모델 개발을 수행하고 있습니다.
- 한국인 칩(K-chip)은 한국인의 특이한 유전 정보가 들어있는 질병 연구용 반도체로, 전장유전체상관분석(GWAS)을 인지장애관련 후보 유전변이를 선별하고, 이를 활용하여 인지장애 예측 인공지능 모델을 구축하고 있습니다.
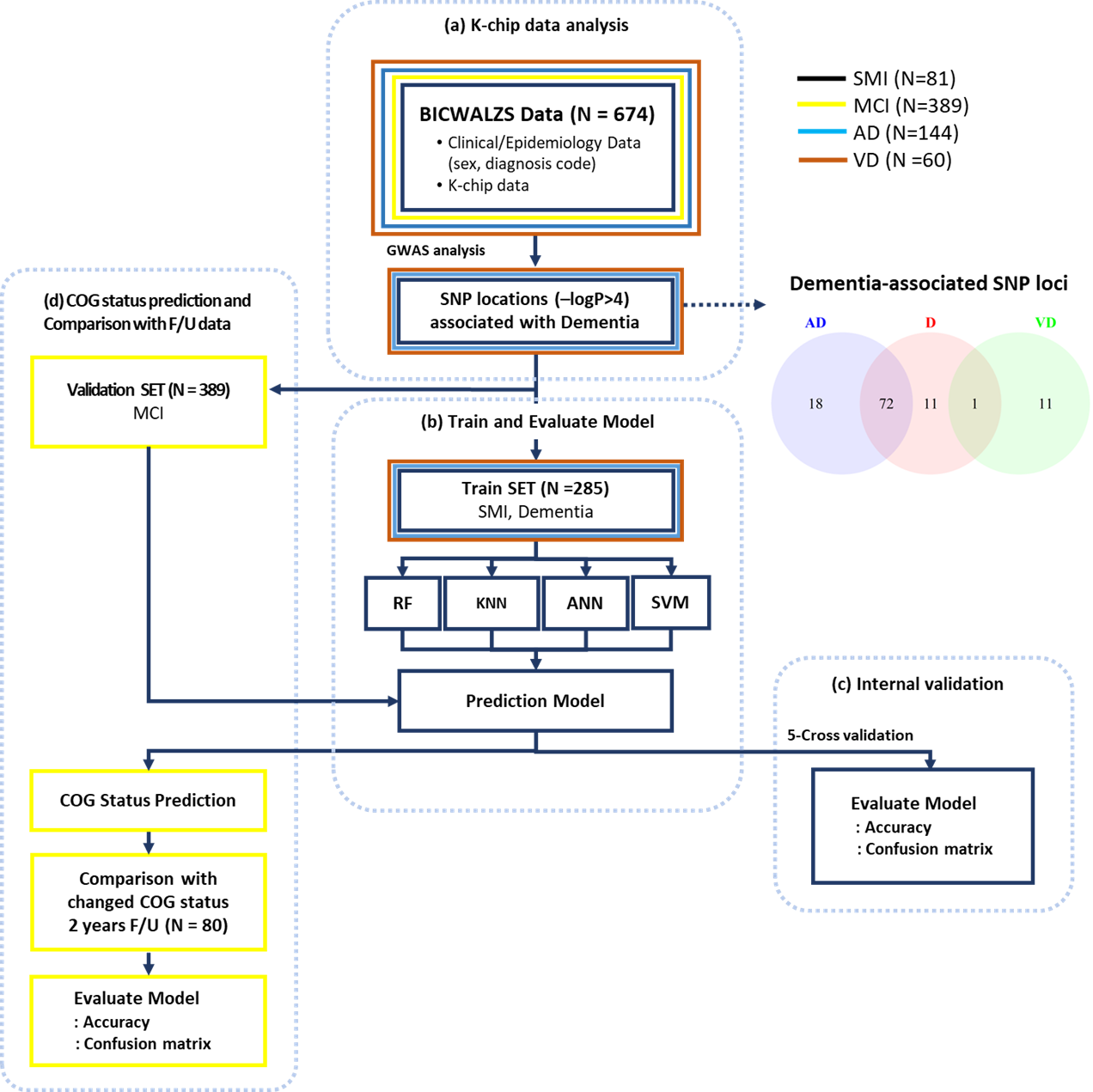
한국인칩 데이터 기반 GWAS 분석을 통한 인지장애 예측 인공지능 모델 구축
-
- 영상·임상역학·인지기능 등의 멀티모달 데이터를 기반으로 인지기능 상태 분류 및 변화 예측을 위한 데이터별 후보 변수를 통계적인 방법으로 선별하고, 이를 활용하여 인공지능 모델을 구축하고 추적관찰 정보를 활용하여 평가를 수행하고 있습니다.
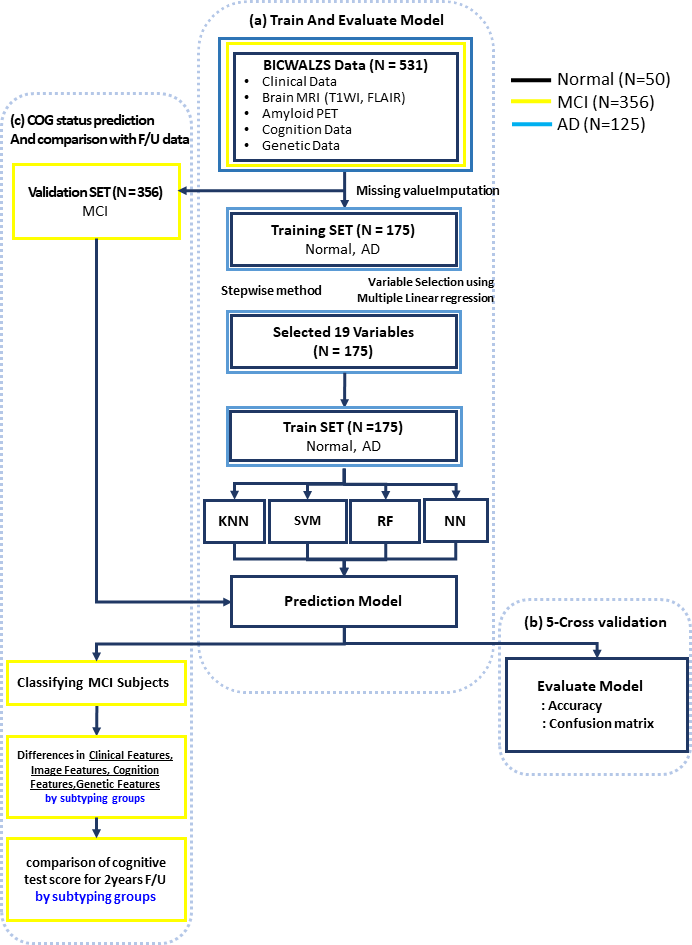
멀티모달 데이터(임상역학, 영상, 유전체) 기반 치매 예측 인공지능 모델 구축
-
다양한 오믹스 정보를 활용하여 코로나19 중증도 예측을 위해, 인공지능 기반의 분류 모델 개발을 수행하고 있습니다.
- 임상역학·혈액검사·사이토카인 발현 정보 등의 멀티모달 데이터를 기반으로 코로나19 중증도 분류 및 예측을 위한 모델을 구축하고, 정확도를 높이기 위해 다양한 접근방법을 활용하여 중요변수 선별, 관련 마커 제시 등을 수행하고 있습니다.
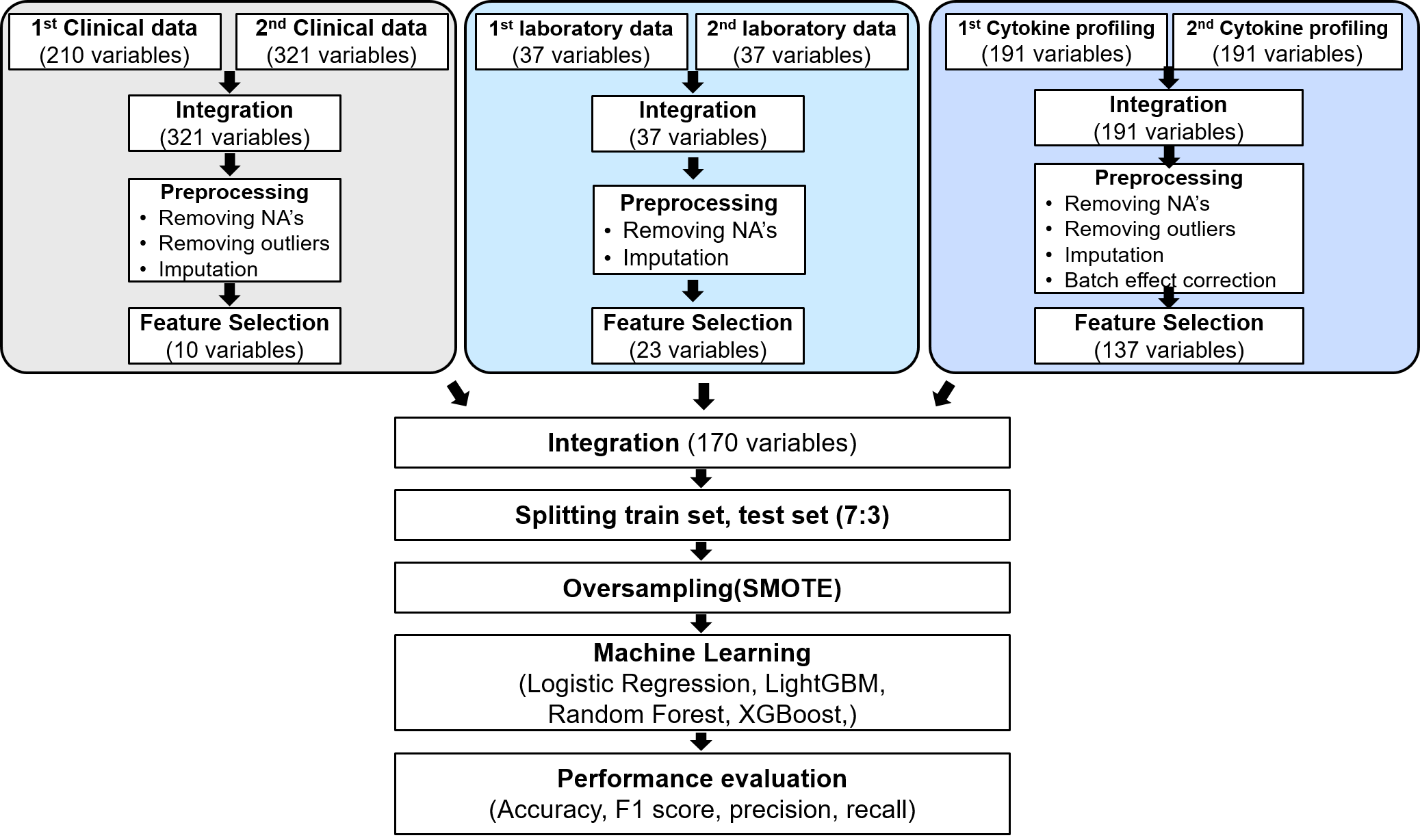
이종데이터 통합분석 파이프라인 구축 및 중증도 예측 모델 개발
- 관련 홈페이지
-
- 질병관리청 누리집 > 간행물·통계 > 간행물 > 질병관리청 백서 외부링크연결
- 문의
- 헬스케어인공지능연구과, 043-719-8853